- Introduction
- Implementation
- Dependencies
- Core functions
- Query and type definition
- N+1 problem
- Interface definition
- Custom scalar definition
- Mutation definition
- Subscription definition
- Integration tests
- GraphQL API client
- API security
- Enum definition
- Work with dates
- Apollo Federation support
- Apollo Server
- Interaction with a database
- Project launch and API testing
- Subscription test
- CI/CD
- Conclusion
- Useful links
This article is also available in Chinese.
In today’s article, I’ll describe how to create a GraphQL backend using Rust and its ecosystem. The article provides examples of an implementation of the most common tasks that can be encountered while creating GraphQL API. Finally, three microservices will be combined into a single endpoint using Apollo Server and Apollo Federation. This allows clients to fetch data from any number of sources simultaneously, without needing to know which data comes from which source.
Introduction
Overview
In terms of functionality described project is quite similar to one described in my previous article, but now it is written using Rust’s stack. The project’s architecture looks like this:
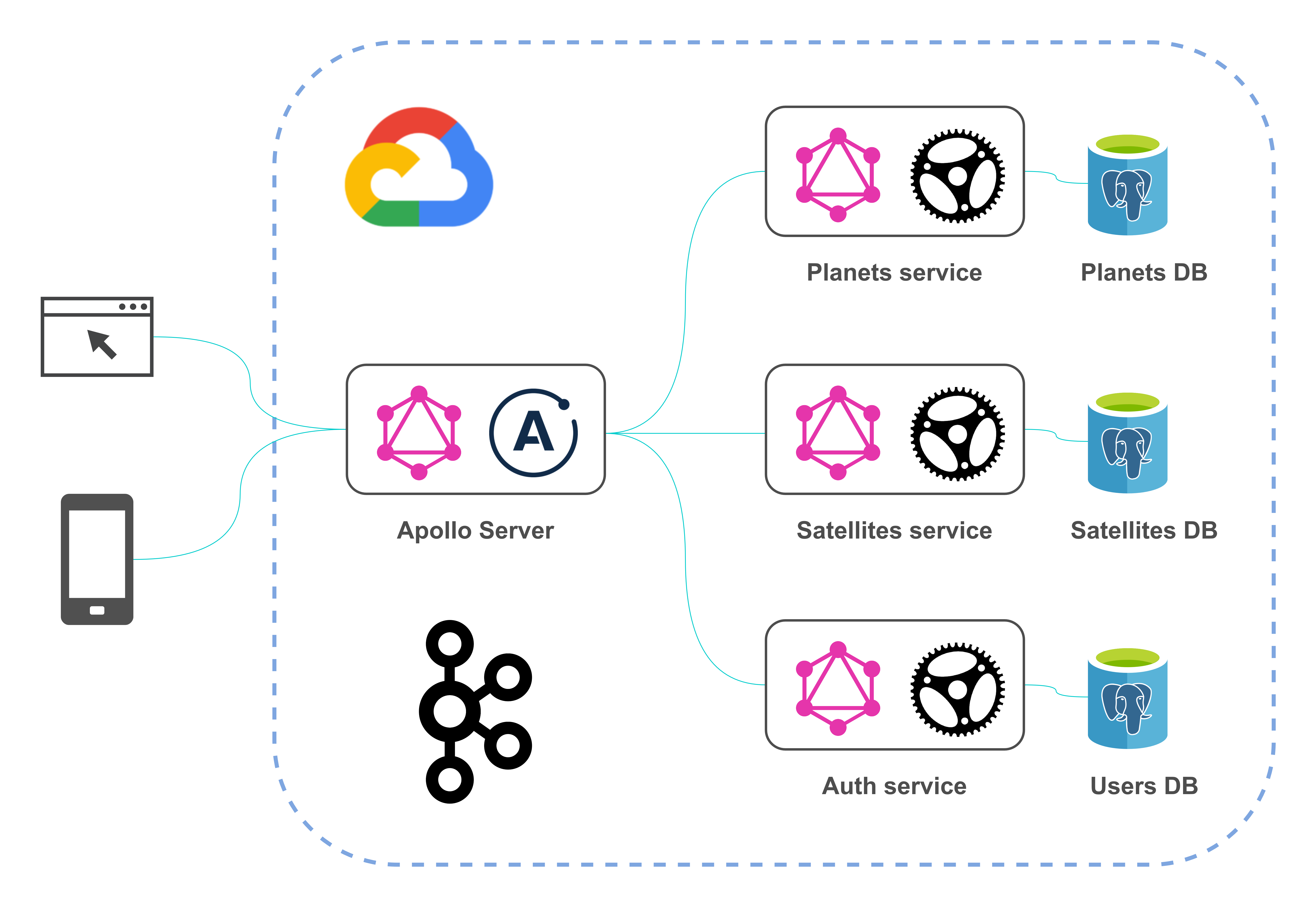
Each component of the architecture answers several questions that may arise when implementing GraphQL API. The domain model includes data about planets in the Solar System and their satellites. The project has a multi-module structure and consists of the following modules:
-
planets-service (Rust)
-
satellites-service (Rust)
-
auth-service (Rust)
-
apollo-server (JS)
There are two main libraries for creating a GraphQL backend in Rust: Juniper and Async-graphql, but only the latter supports Apollo Federation, so I chose it for the project (there is also an open issue for Federation support in Juniper). Both libraries follow the code-first approach.
Also, PostgreSQL is used for persistence layer implementation, JWT — for authentication, and Kafka — for asynchronous messaging.
Stack of technologies
The following table summarizes a stack of main technologies used in the project:
| Type | Name | Site | GitHub |
|---|---|---|---|
Language |
Rust |
||
GraphQL library |
Async-graphql |
||
Single GraphQL endpoint |
Apollo Server |
||
Web framework |
actix-web |
||
Database |
PostgreSQL |
||
Event streaming platform |
Apache Kafka |
||
Container orchestration tool |
Docker Compose |
Also, some other used Rust libraries:
| Type | Name | Site | GitHub |
|---|---|---|---|
ORM |
Diesel |
||
Kafka client |
rust-rdkafka |
||
Password hashing library |
argonautica |
||
JWT library |
jsonwebtoken |
||
Testing library |
Testcontainers-rs |
Prerequisites
To launch the project locally you only need Docker Compose. Without Docker, you might need to install the following:
-
Diesel CLI (to install run
cargo install diesel_cli --no-default-features --features postgres) -
LLVM (this is needed for the
argonauticacrate to work) -
CMake (this is needed for the
rust-rdkafkacrate to work)
Implementation
Root Cargo.toml specifies three applications and one library:
[workspace]
members = [
"auth-service",
"planets-service",
"satellites-service",
"common-utils",
]Let’s start with planets-service.
Dependencies
Cargo.toml looks like this:
[package]
name = "planets-service"
version = "0.1.0"
edition = "2018"
[dependencies]
common-utils = { path = "../common-utils" }
async-graphql = "2.4.3"
async-graphql-actix-web = "2.4.3"
actix-web = "3.3.2"
actix-rt = "1.1.1"
actix-web-actors = "3.0.0"
futures = "0.3.8"
async-trait = "0.1.42"
bigdecimal = { version = "0.1.2", features = ["serde"] }
serde = { version = "1.0.118", features = ["derive"] }
serde_json = "1.0.60"
diesel = { version = "1.4.5", features = ["postgres", "r2d2", "numeric"] }
diesel_migrations = "1.4.0"
dotenv = "0.15.0"
strum = "0.20.0"
strum_macros = "0.20.1"
rdkafka = { version = "0.24.0", features = ["cmake-build"] }
async-stream = "0.3.0"
lazy_static = "1.4.0"
[dev-dependencies]
jsonpath_lib = "0.2.6"
testcontainers = "0.9.1"async-graphql is a GraphQL library, actix-web is a web framework, and async-graphql-actix-web provides integration between them.
Core functions
We’ll go right away to the main.rs:
#[actix_rt::main]
async fn main() -> std::io::Result<()> {
dotenv().ok();
let pool = create_connection_pool();
run_migrations(&pool);
let schema = create_schema_with_context(pool);
HttpServer::new(move || App::new()
.configure(configure_service)
.data(schema.clone())
)
.bind("0.0.0.0:8001")?
.run()
.await
}Here an environment and HTTP server are configured using functions defined in the lib.rs:
pub fn configure_service(cfg: &mut web::ServiceConfig) {
cfg
.service(web::resource("/")
.route(web::post().to(index))
.route(web::get().guard(guard::Header("upgrade", "websocket")).to(index_ws))
.route(web::get().to(index_playground))
);
}
async fn index(schema: web::Data<AppSchema>, http_req: HttpRequest, req: Request) -> Response {
let mut query = req.into_inner();
let maybe_role = common_utils::get_role(http_req);
if let Some(role) = maybe_role {
query = query.data(role);
}
schema.execute(query).await.into()
}
async fn index_ws(schema: web::Data<AppSchema>, req: HttpRequest, payload: web::Payload) -> Result<HttpResponse> {
WSSubscription::start(Schema::clone(&*schema), &req, payload)
}
async fn index_playground() -> HttpResponse {
HttpResponse::Ok()
.content_type("text/html; charset=utf-8")
.body(playground_source(GraphQLPlaygroundConfig::new("/").subscription_endpoint("/")))
}
pub fn create_schema_with_context(pool: PgPool) -> Schema<Query, Mutation, Subscription> {
let arc_pool = Arc::new(pool);
let cloned_pool = Arc::clone(&arc_pool);
let details_batch_loader = Loader::new(DetailsBatchLoader {
pool: cloned_pool
}).with_max_batch_size(10);
let kafka_consumer_counter = Mutex::new(0);
Schema::build(Query, Mutation, Subscription)
.data(arc_pool)
.data(details_batch_loader)
.data(kafka::create_producer())
.data(kafka_consumer_counter)
.finish()
}These functions do the following:
-
index— processes GraphQL queries and mutations -
index_ws— processes GraphQL subscriptions -
index_playground— provides Playground GraphQL IDE -
create_schema_with_context— creates GraphQL schema with global contextual data that are accessible at runtime, for example, a pool of database connections
Query and type definition
Let’s consider how to define a query:
#[Object]
impl Query {
async fn get_planets(&self, ctx: &Context<'_>) -> Vec<Planet> {
repository::get_all(&get_conn_from_ctx(ctx)).expect("Can't get planets")
.iter()
.map(|p| { Planet::from(p) })
.collect()
}
async fn get_planet(&self, ctx: &Context<'_>, id: ID) -> Option<Planet> {
find_planet_by_id_internal(ctx, id)
}
#[graphql(entity)]
async fn find_planet_by_id(&self, ctx: &Context<'_>, id: ID) -> Option<Planet> {
find_planet_by_id_internal(ctx, id)
}
}
fn find_planet_by_id_internal(ctx: &Context<'_>, id: ID) -> Option<Planet> {
let id = id.to_string().parse::<i32>().expect("Can't get id from String");
repository::get(id, &get_conn_from_ctx(ctx)).ok()
.map(|p| { Planet::from(&p) })
}The queries are getting data from a database using a repository. Obtained entities are converted to GraphQL DTO (that
allows us to preserve the single-responsibility principle for each struct). get_planets and get_planet queries can be accessed from any
GraphQL IDE, for example like this:
{
getPlanets {
name
type
}
}Planet struct is defined as follows:
#[derive(Serialize, Deserialize)]
struct Planet {
id: ID,
name: String,
planet_type: PlanetType,
}
#[Object]
impl Planet {
async fn id(&self) -> &ID {
&self.id
}
async fn name(&self) -> &String {
&self.name
}
/// From an astronomical point of view
#[graphql(name = "type")]
async fn planet_type(&self) -> &PlanetType {
&self.planet_type
}
#[graphql(deprecation = "Now it is not in doubt. Do not use this field")]
async fn is_rotating_around_sun(&self) -> bool {
true
}
async fn details(&self, ctx: &Context<'_>) -> Details {
let loader = ctx.data::<Loader<i32, Details, DetailsBatchLoader>>().expect("Can't get loader");
let planet_id = self.id.to_string().parse::<i32>().expect("Can't convert id");
loader.load(planet_id).await
}
}Here we define a resolver for each field. Also, for some fields, description (as Rust’s comment) and deprecation reason are specified. These will be shown in a GraphQL IDE.
N+1 problem
If the definition of details function of Planet above was naive, this would lead to N+1 problem, that is, if you
made such a request:
{
getPlanets {
name
details {
meanRadius
}
}
}then separate SQL call would be executed for details field of each planet because Details is a separate entity
from Planet and is stored in its own table.
But with help of Async-graphql’s implementation of DataLoader details resolver can be defined as follows:
async fn details(&self, ctx: &Context<'_>) -> Result<Details> {
let data_loader = ctx.data::<DataLoader<DetailsLoader>>().expect("Can't get data loader");
let planet_id = self.id.to_string().parse::<i32>().expect("Can't convert id");
let details = data_loader.load_one(planet_id).await?;
details.ok_or_else(|| "Not found".into())
}data_loader is an application-scoped object defined in this way:
let details_data_loader = DataLoader::new(DetailsLoader {
pool: cloned_pool
}).max_batch_size(10);DetailsLoader is implemented like this:
pub struct DetailsLoader {
pub pool: Arc<PgPool>
}
#[async_trait::async_trait]
impl Loader<i32> for DetailsLoader {
type Value = Details;
type Error = Error;
async fn load(&self, keys: &[i32]) -> Result<HashMap<i32, Self::Value>, Self::Error> {
let conn = self.pool.get().expect("Can't get DB connection");
let details = repository::get_details(keys, &conn).expect("Can't get planets' details");
Ok(details.iter()
.map(|details_entity| (details_entity.planet_id, Details::from(details_entity)))
.collect::<HashMap<_, _>>())
}
}This method helps us to prevent N+1 problem because each DetailsLoader.load call executes just one
SQL call returning a bunch of DetailsEntity.
Interface definition
GraphQL interface and its implementations can be defined in this way:
#[derive(Interface, Clone)]
#[graphql(
field(name = "mean_radius", type = "&CustomBigDecimal"),
field(name = "mass", type = "&CustomBigInt"),
)]
pub enum Details {
InhabitedPlanetDetails(InhabitedPlanetDetails),
UninhabitedPlanetDetails(UninhabitedPlanetDetails),
}
#[derive(SimpleObject, Clone)]
pub struct InhabitedPlanetDetails {
mean_radius: CustomBigDecimal,
mass: CustomBigInt,
/// In billions
population: CustomBigDecimal,
}
#[derive(SimpleObject, Clone)]
pub struct UninhabitedPlanetDetails {
mean_radius: CustomBigDecimal,
mass: CustomBigInt,
}Here you can also see that if the structure doesn’t have a single field with a complex resolver, it can be implemented using SimpleObject attribute.
Custom scalar definition
Custom scalars allow defining how to represent a value of some type and how to parse it. The project contains two examples of custom scalar definition; both are wrappers for numeric structures (because you can’t implement an external trait on an external type due to the orphan rule). The wrappers are implemented as follows:
#[derive(Clone)]
pub struct CustomBigInt(BigDecimal);
#[Scalar(name = "BigInt")]
impl ScalarType for CustomBigInt {
fn parse(value: Value) -> InputValueResult<Self> {
match value {
Value::String(s) => {
let parsed_value = BigDecimal::from_str(&s)?;
Ok(CustomBigInt(parsed_value))
}
_ => Err(InputValueError::expected_type(value)),
}
}
fn to_value(&self) -> Value {
Value::String(format!("{:e}", &self))
}
}
impl LowerExp for CustomBigInt {
fn fmt(&self, f: &mut Formatter<'_>) -> fmt::Result {
let val = &self.0.to_f64().expect("Can't convert BigDecimal");
LowerExp::fmt(val, f)
}
}#[derive(Clone)]
pub struct CustomBigDecimal(BigDecimal);
#[Scalar(name = "BigDecimal")]
impl ScalarType for CustomBigDecimal {
fn parse(value: Value) -> InputValueResult<Self> {
match value {
Value::String(s) => {
let parsed_value = BigDecimal::from_str(&s)?;
Ok(CustomBigDecimal(parsed_value))
}
_ => Err(InputValueError::expected_type(value)),
}
}
fn to_value(&self) -> Value {
Value::String(self.0.to_string())
}
}The former example also shows how to represent a large number using exponential (scientific) notation.
Mutation definition
A mutation can be defined as the following:
pub struct Mutation;
#[Object]
impl Mutation {
#[graphql(guard(RoleGuard(role = "Role::Admin")))]
async fn create_planet(&self, ctx: &Context<'_>, planet: PlanetInput) -> Result<Planet, Error> {
let new_planet = NewPlanetEntity {
name: planet.name,
planet_type: planet.planet_type.to_string(),
};
let details = planet.details;
let new_planet_details = NewDetailsEntity {
mean_radius: details.mean_radius.0,
mass: BigDecimal::from_str(&details.mass.0.to_string()).expect("Can't get BigDecimal from string"),
population: details.population.map(|wrapper| { wrapper.0 }),
planet_id: 0,
};
let created_planet_entity = repository::create(new_planet, new_planet_details, &get_conn_from_ctx(ctx))?;
let producer = ctx.data::<FutureProducer>().expect("Can't get Kafka producer");
let message = serde_json::to_string(&Planet::from(&created_planet_entity)).expect("Can't serialize a planet");
kafka::send_message(producer, message).await;
Ok(Planet::from(&created_planet_entity))
}
}To use an object as input parameter of a mutation you need to define a structure in this way:
#[derive(InputObject)]
struct PlanetInput {
name: String,
#[graphql(name = "type")]
planet_type: PlanetType,
details: DetailsInput,
}The mutation is protected by RoleGuard which ensures that only users with Admin role can access it. So to execute
the mutation, for example, like this:
mutation {
createPlanet(
planet: {
name: "test_planet"
type: TERRESTRIAL_PLANET
details: { meanRadius: "10.5", mass: "8.8e24", population: "0.5" }
}
) {
id
}
}you need to specify Authorization header with a JWT obtained from auth-service (this will be described later).
Subscription definition
In the mutation definition above you could see that on a planet creation a message is sent:
let producer = ctx.data::<FutureProducer>().expect("Can't get Kafka producer");
let message = serde_json::to_string(&Planet::from(&created_planet_entity)).expect("Can't serialize a planet");
kafka::send_message(producer, message).await;The API client can be notified of the event by using a subscription that listens to Kafka consumer:
pub struct Subscription;
#[Subscription]
impl Subscription {
async fn latest_planet<'ctx>(&self, ctx: &'ctx Context<'_>) -> impl Stream<Item=Planet> + 'ctx {
let kafka_consumer_counter = ctx.data::<Mutex<i32>>().expect("Can't get Kafka consumer counter");
let consumer_group_id = kafka::get_kafka_consumer_group_id(kafka_consumer_counter);
let consumer = kafka::create_consumer(consumer_group_id);
async_stream::stream! {
let mut stream = consumer.start();
while let Some(value) = stream.next().await {
yield match value {
Ok(message) => {
let payload = message.payload().expect("Kafka message should contain payload");
let message = String::from_utf8_lossy(payload).to_string();
serde_json::from_str(&message).expect("Can't deserialize a planet")
}
Err(e) => panic!("Error while Kafka message processing: {}", e)
};
}
}
}
}A subscription can be used like queries and mutations:
subscription {
latestPlanet {
id
name
type
details {
meanRadius
}
}
}Subscription URL is ws://localhost:8001.
Integration tests
Tests for queries and mutations can be written like this:
#[actix_rt::test]
async fn test_get_planets() {
let docker = Cli::default();
let (_pg_container, pool) = common::setup(&docker);
let mut service = test::init_service(App::new()
.configure(configure_service)
.data(create_schema_with_context(pool))
).await;
let query = "
{
getPlanets {
id
name
type
details {
meanRadius
mass
... on InhabitedPlanetDetails {
population
}
}
}
}
".to_string();
let request_body = GraphQLCustomRequest {
query,
variables: Map::new(),
};
let request = test::TestRequest::post().uri("/").set_json(&request_body).to_request();
let response: GraphQLCustomResponse = test::read_response_json(&mut service, request).await;
fn get_planet_as_json(all_planets: &serde_json::Value, index: i32) -> &serde_json::Value {
jsonpath::select(all_planets, &format!("$.getPlanets[{}]", index)).expect("Can't get planet by JSON path")[0]
}
let mercury_json = get_planet_as_json(&response.data, 0);
common::check_planet(mercury_json, 1, "Mercury", "TERRESTRIAL_PLANET", "2439.7");
let earth_json = get_planet_as_json(&response.data, 2);
common::check_planet(earth_json, 3, "Earth", "TERRESTRIAL_PLANET", "6371.0");
let neptune_json = get_planet_as_json(&response.data, 7);
common::check_planet(neptune_json, 8, "Neptune", "ICE_GIANT", "24622.0");
}If a part of a query can be reused in another query, you can use fragments:
const PLANET_FRAGMENT: &str = "
fragment planetFragment on Planet {
id
name
type
details {
meanRadius
mass
... on InhabitedPlanetDetails {
population
}
}
}
";
#[actix_rt::test]
async fn test_get_planet_by_id() {
...
let query = "
{
getPlanet(id: 3) {
... planetFragment
}
}
".to_string() + PLANET_FRAGMENT;
let request_body = GraphQLCustomRequest {
query,
variables: Map::new(),
};
...
}To use variables, you can write test in this way:
#[actix_rt::test]
async fn test_get_planet_by_id_with_variable() {
...
let query = "
query testPlanetById($planetId: String!) {
getPlanet(id: $planetId) {
... planetFragment
}
}".to_string() + PLANET_FRAGMENT;
let jupiter_id = 5;
let mut variables = Map::new();
variables.insert("planetId".to_string(), jupiter_id.into());
let request_body = GraphQLCustomRequest {
query,
variables,
};
...
}In this project, Testcontainers-rs library is used to prepare test environment, that is, to create a temporary PostgreSQL database.
GraphQL API client
You can use code snippets from the previous section to create a client to an external GraphQL API. Also, there are special libraries for this purpose, for example, graphql-client, but I haven’t used them yet.
API security
There are different security threats to your GraphQL API (see this checklist to learn more); let’s consider some of these aspects.
Query depth and complexity limit
If the Satellite structure contained planet field, the following request would be possible:
{
getPlanet(id: "1") {
satellites {
planet {
satellites {
planet {
satellites {
... # more deep nesting!
}
}
}
}
}
}
}To make such a request invalid we can specify:
pub fn create_schema_with_context(pool: PgPool) -> Schema<Query, Mutation, Subscription> {
...
Schema::build(Query, Mutation, Subscription)
.limit_depth(3)
.limit_complexity(15)
...
}Note that if you specify depth or complexity limit, then documentation of a service may stop showing in your GraphQL IDE. This is because the IDE tries to perform an introspection query that has considerable depth and complexity.
Authentication
This functionality is implemented in auth-service
using argonautica and jsonwebtoken crates. The former crate is responsible for a user’s password hashing
using Argon2 algorithm. Authentication and authorization functionality is only for demo; please do more
research for production use.
Let’s consider how signing in is implemented:
pub struct Mutation;
#[Object]
impl Mutation {
async fn sign_in(&self, ctx: &Context<'_>, input: SignInInput) -> Result<String, Error> {
let maybe_user = repository::get_user(&input.username, &get_conn_from_ctx(ctx)).ok();
if let Some(user) = maybe_user {
if let Ok(matching) = verify_password(&user.hash, &input.password) {
if matching {
let role = AuthRole::from_str(user.role.as_str()).expect("Can't convert &str to AuthRole");
return Ok(common_utils::create_token(user.username, role));
}
}
}
Err(Error::new("Can't authenticate a user"))
}
}
#[derive(InputObject)]
struct SignInInput {
username: String,
password: String,
}You can check the implementation of verify_password function in utils module
and create_token in common_utils module. As
you may expect, sign_in function issues JWT that further can be used for authorization in other services.
To get a JWT you need to perform the following mutation:
mutation {
signIn(input: { username: "john_doe", password: "password" })
}For that, you can use john_doe/password credentials. Including obtained JWT to further requests allows access to protected resources (see next section).
Authorization
To request protected data you need to add a header to an HTTP request in the format Authorization: Bearer $JWT. index
function will extract a user’s role from the request and will add it to a query data:
async fn index(schema: web::Data<AppSchema>, http_req: HttpRequest, req: Request) -> Response {
let mut query = req.into_inner();
let maybe_role = common_utils::get_role(http_req);
if let Some(role) = maybe_role {
query = query.data(role);
}
schema.execute(query).await.into()
}The following attribute was applied to create_planet mutation defined earlier:
#[graphql(guard(RoleGuard(role = "Role::Admin")))]Guard itself is implemented as follows:
struct RoleGuard {
role: Role,
}
#[async_trait::async_trait]
impl Guard for RoleGuard {
async fn check(&self, ctx: &Context<'_>) -> Result<()> {
if ctx.data_opt::<Role>() == Some(&self.role) {
Ok(())
} else {
Err("Forbidden".into())
}
}
}So if you don’t specify a token, the server will respond with a message containing "Forbidden".
Enum definition
GraphQL enum can be defined in this way:
#[derive(SimpleObject)]
struct Satellite {
...
life_exists: LifeExists,
}
#[derive(Copy, Clone, Eq, PartialEq, Debug, Enum, EnumString)]
#[strum(serialize_all = "SCREAMING_SNAKE_CASE")]
pub enum LifeExists {
Yes,
OpenQuestion,
NoData,
}Work with dates
Async-graphql supports date/time types from chrono library, so you can define such fields as usual:
#[derive(SimpleObject)]
struct Satellite {
...
first_spacecraft_landing_date: Option<NaiveDate>,
}Apollo Federation support
One of the purposes of satellites-service is to demonstrate how the distributed GraphQL entity
(Planet) can be resolved in two (or more) services and then accessed through Apollo Server.
Planet type was earlier defined in the planets-service in this way:
Planet type in planets-service#[derive(Serialize, Deserialize)]
struct Planet {
id: ID,
name: String,
planet_type: PlanetType,
}Also, in planets-service Planet type is an entity:
Planet entity definition#[Object]
impl Query {
#[graphql(entity)]
async fn find_planet_by_id(&self, ctx: &Context<'_>, id: ID) -> Option<Planet> {
find_planet_by_id_internal(ctx, id)
}
}satellites-service extends Planet entity by adding the satellites field to it:
Planet type in satellites-servicestruct Planet {
id: ID
}
#[Object(extends)]
impl Planet {
#[graphql(external)]
async fn id(&self) -> &ID {
&self.id
}
async fn satellites(&self, ctx: &Context<'_>) -> Vec<Satellite> {
let id = self.id.to_string().parse::<i32>().expect("Can't get id from String");
repository::get_by_planet_id(id, &get_conn_from_ctx(ctx)).expect("Can't get satellites of planet")
.iter()
.map(|e| { Satellite::from(e) })
.collect()
}
}You should also provide a lookup function for an extended type (here it just creates a new instance of Planet):
Planet type#[Object]
impl Query {
#[graphql(entity)]
async fn get_planet_by_id(&self, id: ID) -> Planet {
Planet { id }
}
}Async-graphql generates two additional queries (_service and _entities) that will be used by Apollo Server. These
queries are internal, i.e., they won’t be exposed by Apollo Server. Of course, a service with Apollo Federation support
can still work independently.
Apollo Server
Apollo Server and Apollo Federation allow achieving 2 main goals:
-
create a single endpoint to access GraphQL APIs provided by multiple services
-
create a single data graph from distributed entities
That is, even if you don’t use federated entities, it is more convenient for frontend developers to use a single endpoint rather than multiple endpoints.
There is another way for creating a single GraphQL schema, schema stitching, but I haven’t used this approach.
This module includes the following sources:
{
"name": "api-gateway",
"main": "gateway.js",
"scripts": {
"start-gateway": "nodemon gateway.js"
},
"devDependencies": {
"concurrently": "5.3.0",
"nodemon": "2.0.6"
},
"dependencies": {
"@apollo/gateway": "0.21.3",
"apollo-server": "2.19.0",
"graphql": "15.4.0"
}
}const {ApolloServer} = require("apollo-server");
const {ApolloGateway, RemoteGraphQLDataSource} = require("@apollo/gateway");
class AuthenticatedDataSource extends RemoteGraphQLDataSource {
willSendRequest({request, context}) {
if (context.authHeaderValue) {
request.http.headers.set('Authorization', context.authHeaderValue);
}
}
}
let node_env = process.env.NODE_ENV;
function get_service_url(service_name, port) {
let host;
switch (node_env) {
case 'docker':
host = service_name;
break;
case 'local': {
host = 'localhost';
break
}
}
return "http://" + host + ":" + port;
}
const gateway = new ApolloGateway({
serviceList: [
{name: "planets-service", url: get_service_url("planets-service", 8001)},
{name: "satellites-service", url: get_service_url("satellites-service", 8002)},
{name: "auth-service", url: get_service_url("auth-service", 8003)},
],
buildService({name, url}) {
return new AuthenticatedDataSource({url});
},
});
const server = new ApolloServer({
gateway, subscriptions: false, context: ({req}) => ({
authHeaderValue: req.headers.authorization
})
});
server.listen({host: "0.0.0.0", port: 4000}).then(({url}) => {
console.log(`🚀 Server ready at ${url}`);
});If the source above can be simplified, feel free to contact me for change.
Authorization in apollo-service works as was described earlier for Rust services (you just need to specify Authorization header and its value).
An application written in any language or framework can be added as a downstream service to Apollo Server if it implements Federation specification; a list of libraries that offer such support is available in the documentation.
While implementing this module, I encountered some limitations:
-
Apollo Gateway doesn’t support subscriptions (but they still work in a standalone Rust GraphQL application)
-
a service trying to extend a GraphQL interface requires knowledge of concrete implementations
Interaction with a database
The persistence layer is implemented using PostgreSQL and Diesel. If you don’t use Docker locally, you should run
diesel setup being in each service’s folder. This will create an empty database to which then will be applied migrations
creating tables and inserting data.
Project launch and API testing
As was mentioned before, for launching the project locally you have two options:
-
using Docker Compose (docker-compose.yml)
In its turn, here you also have two options:
-
development mode (using locally built images)
docker-compose up --build -
production mode (using released images)
docker-compose -f docker-compose.yml up
-
-
without Docker
Start each Rust service using
cargo run, then start Apollo Server:-
cdto theapollo-serverfolder -
define
NODE_ENVvariable, for example,set NODE_ENV=local(for Windows) -
npm install -
npm run start-gateway
-
A successful launch of apollo-server should look like this:
[nodemon] 2.0.6
[nodemon] to restart at any time, enter `rs`
[nodemon] watching path(s): *.*
[nodemon] watching extensions: js,mjs,json
[nodemon] starting `node gateway.js`
Server ready at http://0.0.0.0:4000/You can navigate to http://localhost:4000 in your browser and use a built-in Playground IDE:
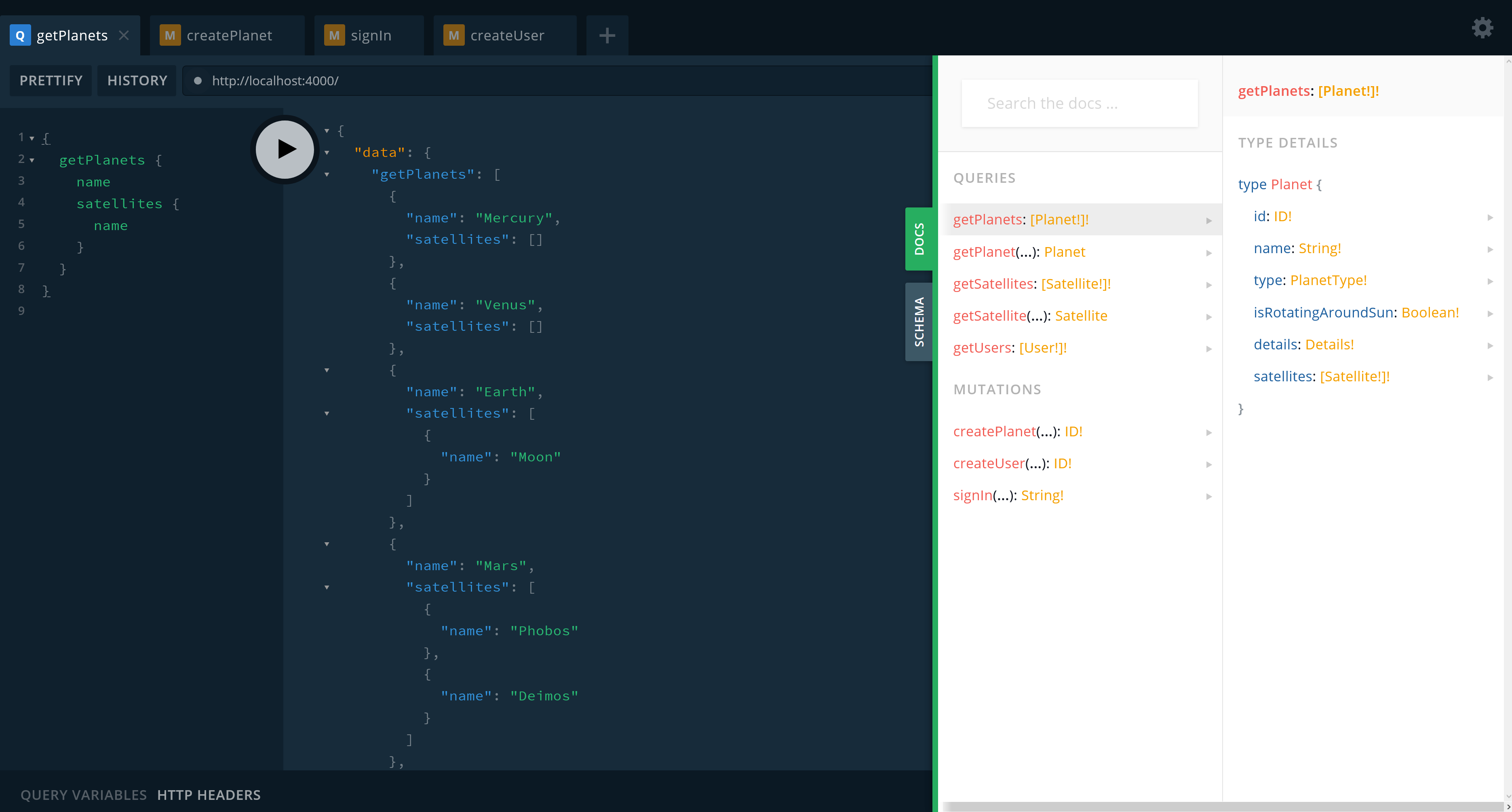
Here you can execute queries, mutations, and subscriptions defined in downstream services. Also, each of those services has its own Playground IDE.
Subscription test
To test whether the subscription works open two tabs of any GraphQL IDE; in the first subscribe as follows:
subscription {
latestPlanet {
name
type
}
}In the second specify Authorization header as was described above and perform mutation like this:
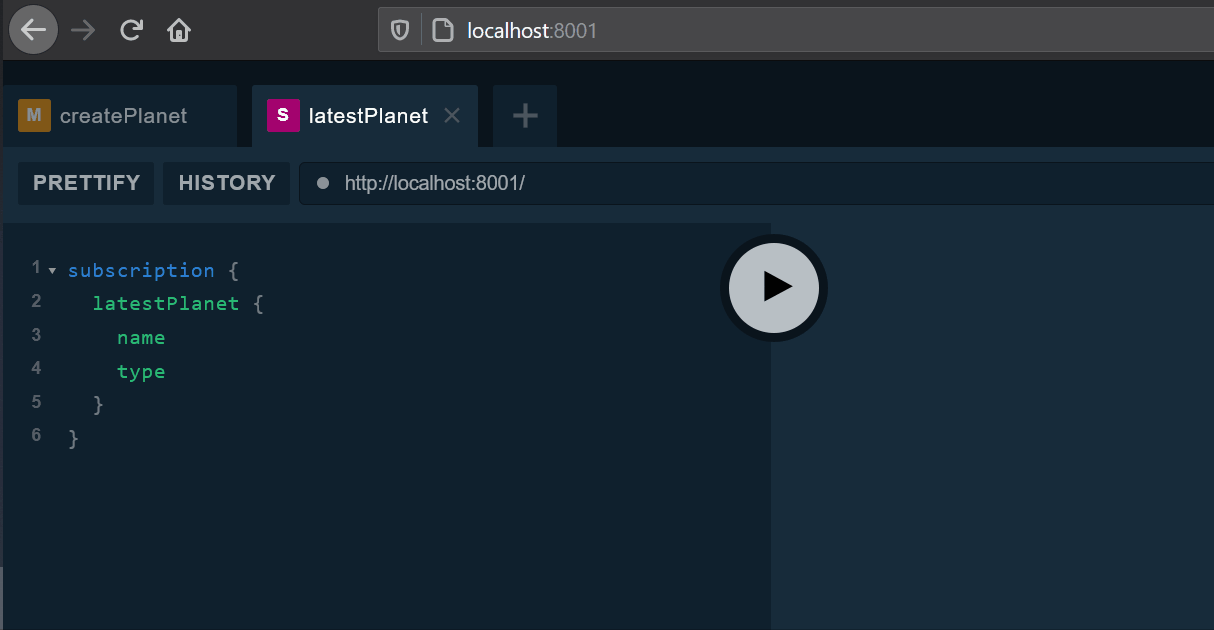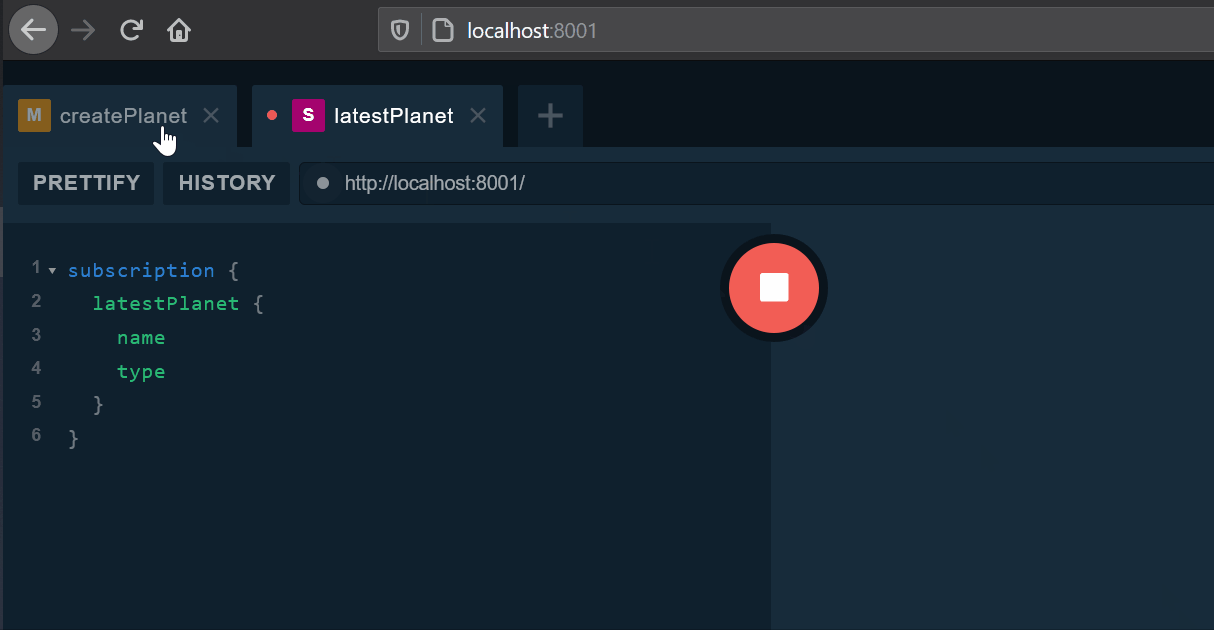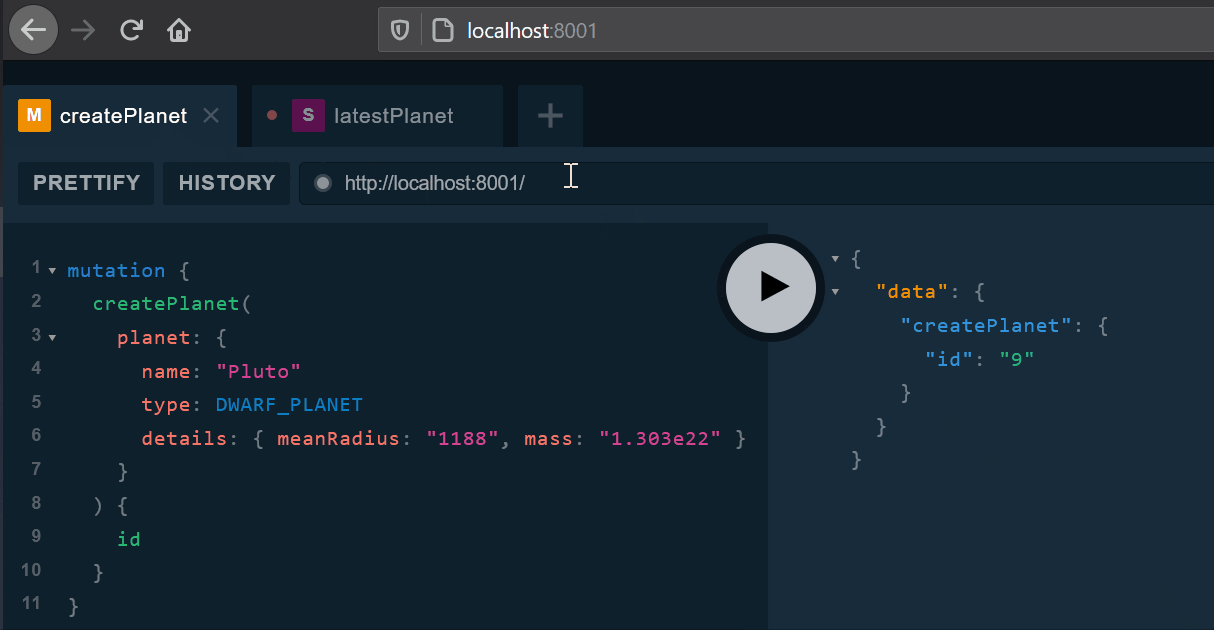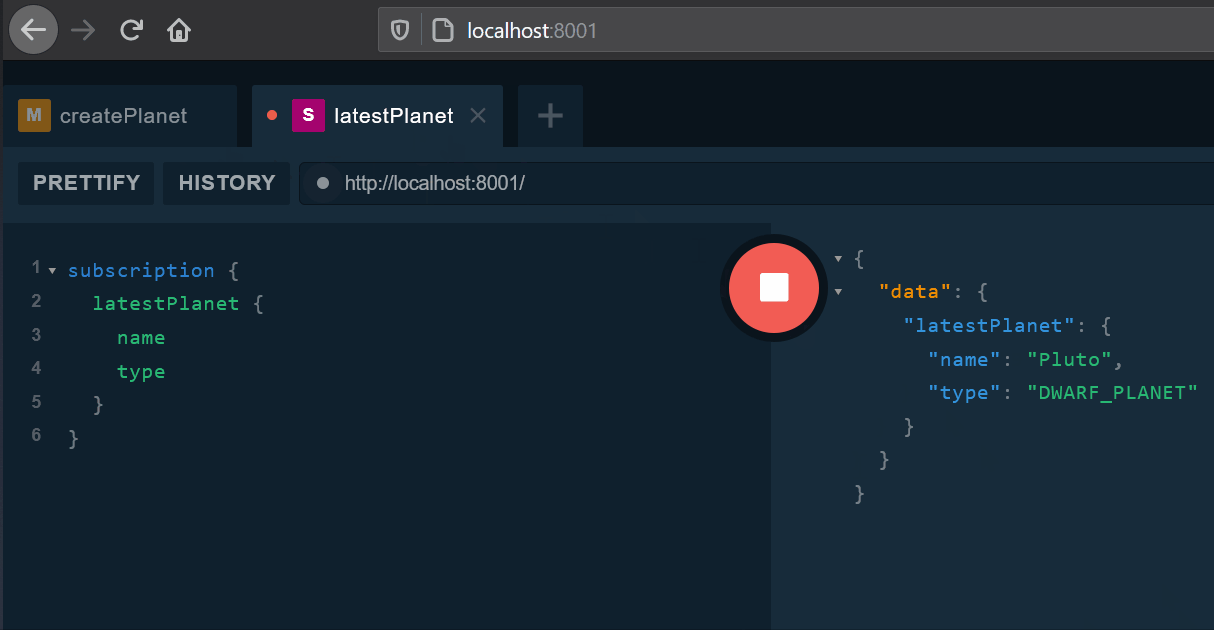
mutation {
createPlanet(
planet: {
name: "Pluto"
type: DWARF_PLANET
details: { meanRadius: "1188", mass: "1.303e22" }
}
) {
id
}
}The subscribed client will be notified of a planet creation:
CI/CD
CI/CD is configured using GitHub Actions (workflow) that runs applications' tests, builds their Docker images, and deploys them on Google Cloud Platform.
You can take a look at the described API here.
Note: On the "production" environment password is different from the one specified earlier to prevent changing initial data.
Conclusion
In this article, I considered how to solve the most common problems that can arise while developing GraphQL API in Rust. Also, I showed how to combine APIs of Rust GraphQL microservices to provide a unified GraphQL interface; in such an architecture an entity can be distributed among several microservices. It is achieved by using Apollo Server, Apollo Federation, and Async-graphql library. The source code of the considered project is on GitHub. Feel free to contact me if you have found any mistakes in the article or the source code. Thanks for reading!